Sábado, 27 de junho de 2015
Do Observatório da Imprensa
http://observatoriodaimprensa.com.br
Dois temas ligados à privacidade e
guarda de dados digitais de usuários da web chamaram minha atenção nos
último dias: o primeiro foi o lançamento de um novo motor de buscas que
não rastreia os usuários nem mantém bancos de dados sobre seus utentes. O
segundo tema trata do que podemos fazer para combater tanta
vulnerabilidade em nossa navegação na web, em grande parte facilitada
pela arquitetura (desenho) de nossos navegadores (ou browsers).
O quão vulnerável é o seu navegador? Ou o meu? Você sabia que, de
acordo com as suas configurações, você pode estar mais ou menos exposto a
invasões e espionagem? Há um site na web que mostra o quão frágeis
somos na web diante de identificadores digitais das grandes corporações e
sites da rede, que insistem em tentar provar que precisam conhecer
nossas vidas a fundo para nos oferecerem “serviços customizados”.
Quanto à nova ferramenta de buscas, ela é um instrumento da era
pós-Edward Snowden, totalmente construída com software de licença livre.
A ampla colaboração entre a Agência Nacional de Informação (NSA)
norte-americana e a mídia social (nomeadamente o Google e o Facebook)
durante a vigência da “Lei Patriótica”, ajudou a espionar mais de 320
milhões de cidadãos comuns na vã tentativa de localizar 300 perfis
suspeitos. Isso serviu para alertar a população americana sobre a
ousadia inconstitucional da agência de segurança americana e abriu
espaço para o surgimento de um novo nicho no mercado de buscas e
pesquisas na web: a consulta sem rastreio, captura de dados e do IP dos
usuários.
O International Business Times
(16/6) anunciou a expansão recente de um novo motor de buscas que não
coleta ou armazena dados dos buscadores. Apresenta respostas em tempo
muito rápido porque não perde tempo a rastrear os internautas que são
usuários do serviço (o DuckDuckGo)
e capta informação de um número grande de fontes e outros buscadores
online. Além de garimpar seu próprio conteúdo. Chegou o “anti-google”.
Criado em 2008 por Gabriel Weinberg, físico e mestre em Tecnologia e
Política pelo Instituto de Tecnologia de Massachusetts (MIT), a ideia
original nunca foi competir com a plataforma que tem o monopólio de fato
das buscas na web, mas crescer entre um público alternativo que precisa
de privacidade para pesquisar sem ser seguido na web. O Google dominou o
mercado de buscas de tal forma que não há condição de um concorrente
crescer a não ser em pequenos nichos. Vejamos sua posição no mundo:
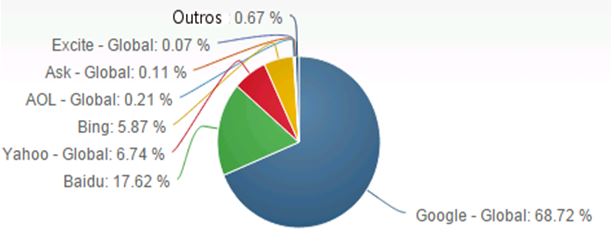
Fonte: netmarketshare.com, 21/6/2015
Resultados impressionantes
O DuckDuckGo surgiu em 2008 com a ideia de oferecer mais respostas instantâneas e menos spam aos pesquisadores da web, através de um sistema híbrido de coleta de informação por meio de crowdsourcing,
outros serviços de busca (todos menos o Google) e seu próprio
rastreador, o DuckDuckBot. Em janeiro de 2009, seu idealizador resolveu
não coletar ou compartilhar dados de usuários. Em 2011, Gabriel Weinberg
e alguns auxiliares estabeleceram a sede do site na cidade de Paoli, na
Pensilvânia. Em fevereiro de 2012, alcançaram o número de um milhão de
buscas realizadas por dia.
Nos últimos dois anos o site de buscas cresceu 600% e já abriu seu caminho para o browser
da Apple, o Safári. Isto não é muito: o Google, em seus anos iniciais
(1998 e 1999), crescia a 17.000 % ao ano. O site Infostats (2015)
informou que hoje o Google processa “mais de 40 mil consultas por
segundo, o que se traduz em mais de 3,5 bilhões de buscas por dia e 1,2
trilhão de buscas por ano em todo o mundo”. Se o leitor quiser comprovar
visualmente o poder colossal do Google, clique aqui e espante-se diante do volume de consultas que o gigante das buscas processa por todo o planeta.
O site de Weinberg não poderia nunca concorrer com isso. Nada vai
abalar o domínio do Google nas buscas. Tudo o que ele oferece é uma
interface amiga, intuitiva, um pouco mais pobre, mas não muito diferente
de seu “concorrente” gigante. Só que muito mais simples e sem ofertas
de serviços e aplicativos “gratuitos” que capturam seus dados na web.
Seu grande diferencial é a privacidade: nem o IP dos usuários é
registrado. O site conta com uma boa base de URLs cadastradas e as
respostas às buscas são rápidas e organizadas. O novo site de buscas é
financiado por anúncios ligados as pesquisas dos usuários e tem um bom
potencial para crescimento.
O trabalho ainda está em andamento, há muito a ser feito e bastante
espaço para melhorias, aperfeiçoamentos e crescimento de buscas sem
rastreio, espionagem ou coleta de dados de usuários. Os resultados das
buscas do novo motor são impressionantes, de alta qualidade em conteúdo e
tem tudo para levar a startup para cima.
A identificação do navegador
A outra questão a ser avaliada é a vulnerabilidade de nossos
navegadores da web (Mozilla, Explorer, Chrome, Safári e outros) a
invasões e ataques contra nossas privacidades. Muitas vezes não cuidamos
o suficiente da proteção de nosso tempo na rede ou de nossa presença
online. Em 2012, a CNET (30/1) publicou um artigo
que ensinava o internauta a prevenir-se das investidas do Google contra
a privacidade dos navegantes, baseada na teoria da entropia. Que é uma
medida matemática calculada em bits que nos permite medir o quão perto
está um elemento a ponto de identificar uma pessoa específica na web.
Os elementos que, juntos, podem identificar alguém na web são o sexo,
o dia ou mês de seu nascimento e seu código postal. Os três juntos,
mais uma sequência de operações matemáticas, geram uma fórmula capaz de
prever o grau de vulnerabilidade de seu navegador na web. Alguém na rede
pode ser identificado a partir de 33 bits de entropia. Mas como saber o
exato número de nossa vulnerabilidade ou possibilidade de identificação
na web? Como saber se somos alvo fácil ou difícil para localização na
web por terceiros indesejáveis?
O artigo da CNET apresentou o trabalho (site) da Fundação Fronteira
Eletrônica (The Electronic Frontier Foundation), que diz na hora qual é o
seu grau de entropia, ou o quão fácil (ou não) é localizar você na web: é o Panoptclick: clique neste link
e ele dirá se seu navegador o deixa mais ou menos capaz de ser
localizado ou rastreado na web. Qualquer número igual ou acima de 33
revela um navegador de fácil identificação.
As vítimas dos caçadores de dados
Fiz o teste e marquei 22,39 bits de informação identificável. Meu browser
não é fácil de identificar ou tracejar na web. E eu consegui isto
apenas escolhendo entre as opções de privacidade oferecidas pelo meu
próprio navegador: abri a sua página de configurações e escolhi não
permitir que outros sites rastreiem minhas rotas na web. Além de outras
opções que expõem o internauta na rede. Nada complicado. Qualquer um
pode fazer isso. Mas pouca gente na América ou no Brasil parece
preocupar-se muito com privacidade. Os europeus foram os únicos a
estabelecer autoridades estatutárias encarregadas da defesa dos dados
dos usuários da internet.
Não basta apenas reclamar dos abusos, da espionagem ou da captação de
nossos dados pessoais pelas megaplataformas do Vale do Silício. Ou
tampouco confiar nas medidas de segurança de sites da web: temos que
fazer a nossa parte e cuidar de nossas próprias defesas. Com pequenas
modificações nas configurações de segurança e privacidade em nossos
navegadores (como a “limpeza” habitual dos dados de navegação), podemos
deixar as coisas mais difíceis para espiões da web, sejam eles estatais
ou privados. Precisamos aprender a regular nossas configurações de
segurança de navegação. Ou pagar o preço da indiferença aos perigos da
web e seus “serviços gratuitos” oferecidos por grandes corporações
tecnológicas.
Tudo isso não vai nos deixar invisíveis ou à prova de ataques na
rede, nem evitará os abusos contra a privacidade de nossos dados na web.
Mas vai permitir que não sejamos mais as primeiras e óbvias vítimas dos
caçadores de dados e transmissores de spam da web.
***
Sergio da Motta e Albuquerque é mestre em Planejamento urbano, consultor e tradutor

